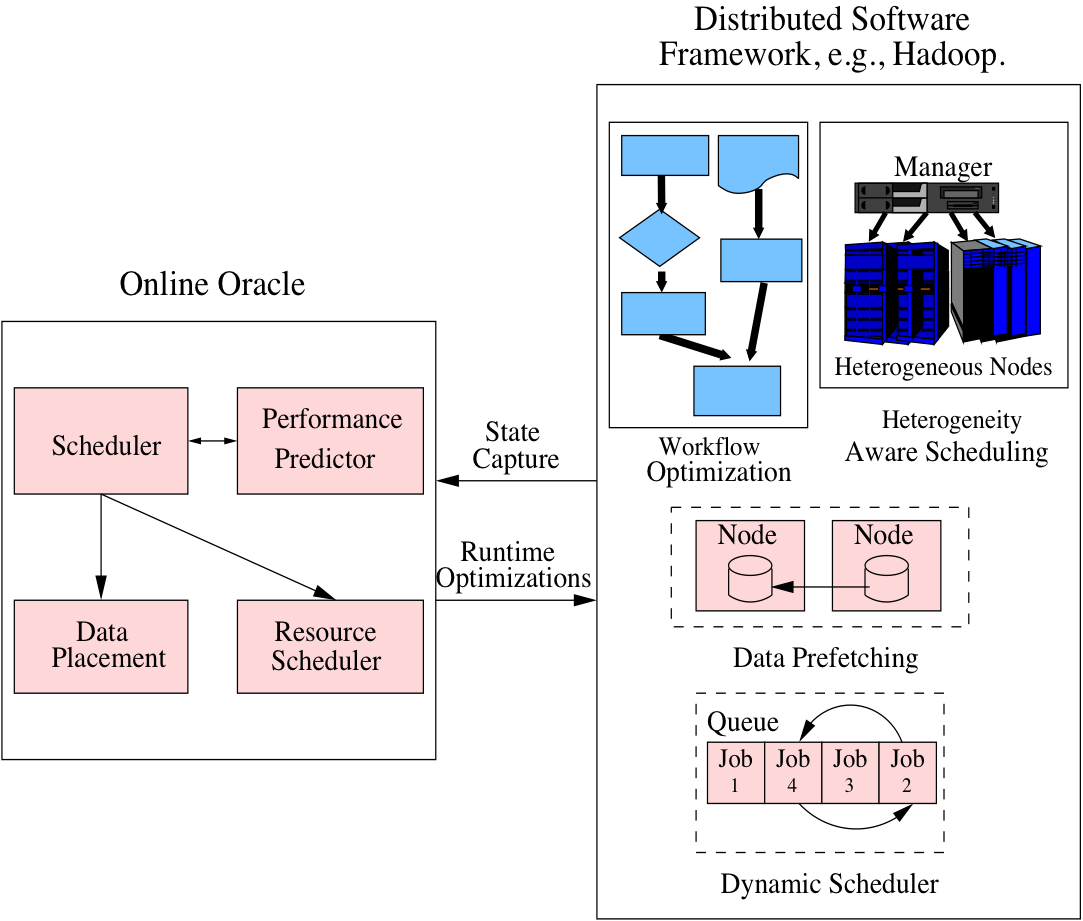
Pythia exploits compile time User-Defined Functions analysis and integrated online simulations of DSF runtimes to provide a comprehensive solution for efficient DSF resource management and scheduling. The scientific value and innovation of this research can be summarized as three tightly-coupled research tasks that enable the development of Pythia, which will achieve efficient resource management for large-scale data management systems such as Hadoop.
Task 1: Design an accurate application classifier using compile-time program analysis that captures workflow behavior and application characteristics, and provides detailed insights into expected runtime application interactions.
Task 2: Design and develop an accurate simulation model that incorporates workflow and application characteristics into a heuristics engine to predict how the application will perform under given conditions and resources.
Task 3: Design a distributed, flexible, efficient, and easy-to-use online oracle framework that captures the infrastructure heterogeneity and integrates with live systems to predict application behavior, which in turn can help guide application-attuned resource scheduling and management.
Relates to Computer Systems Research because the new compile-time and runtime optimizations will enable warehouse-scale Distributed Software Frameworks (DSFs).
Research is motivated by the need to handle the increasing heterogeneity in DSF infrastructure and emerging multi-faceted applications.
Critical gap to be addressed is making DSFs aware of heterogeneity.
Vertically advances the field by designing Pythia that integrates compiler-provided information into holistic simulations and drives efficient DSF resource scheduling and management.
Transformative because Pythia will enable DSFs to efficiently handle heterogeneity in datacenters and support complex emerging applications.
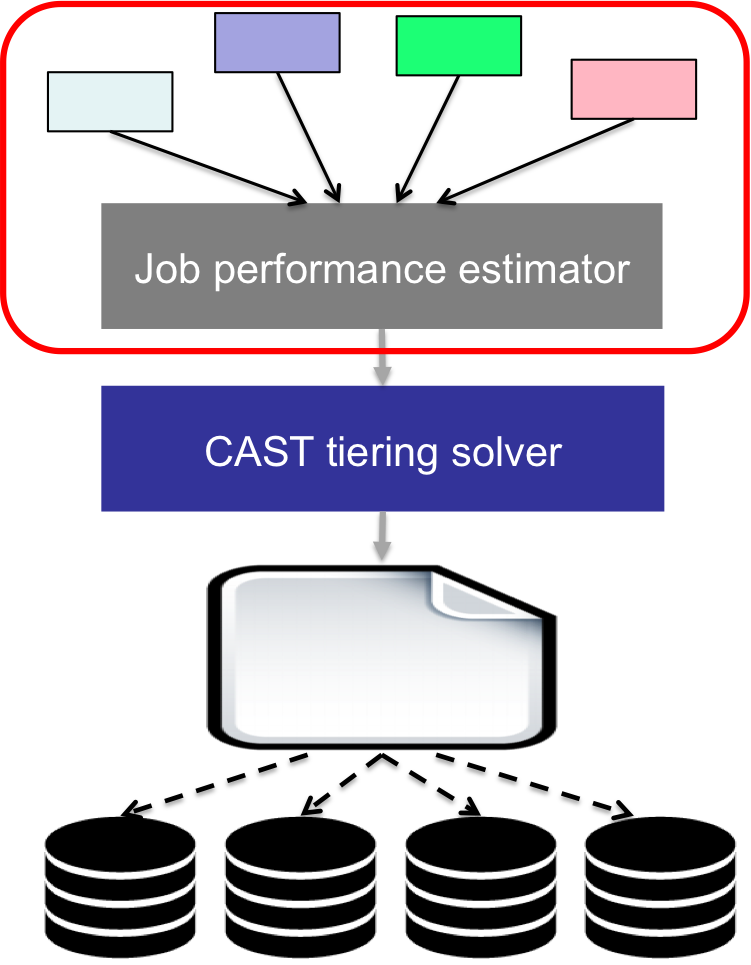
CAST: Cloud Data Analytics Storage Tiering[HPDC’15]
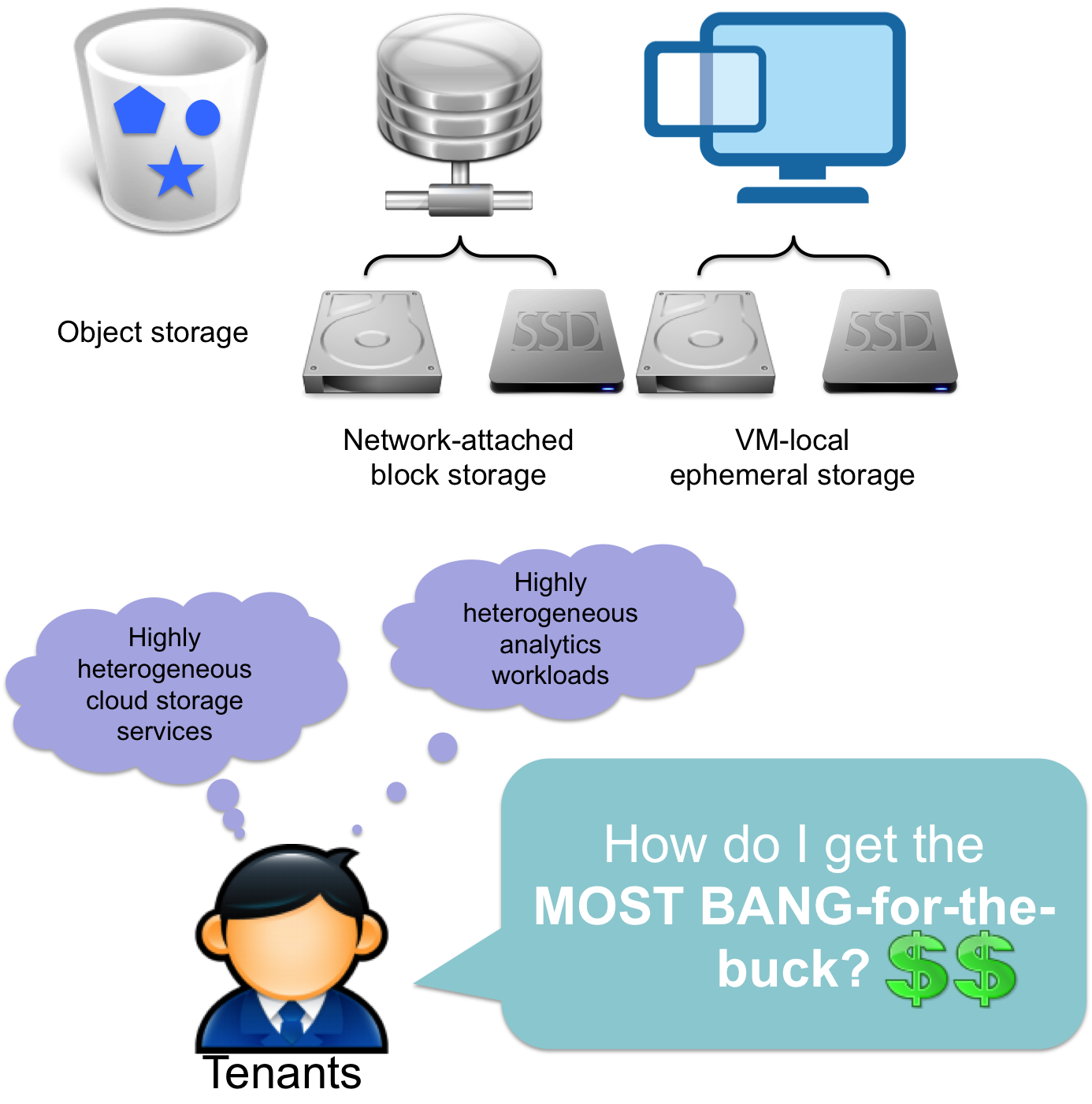
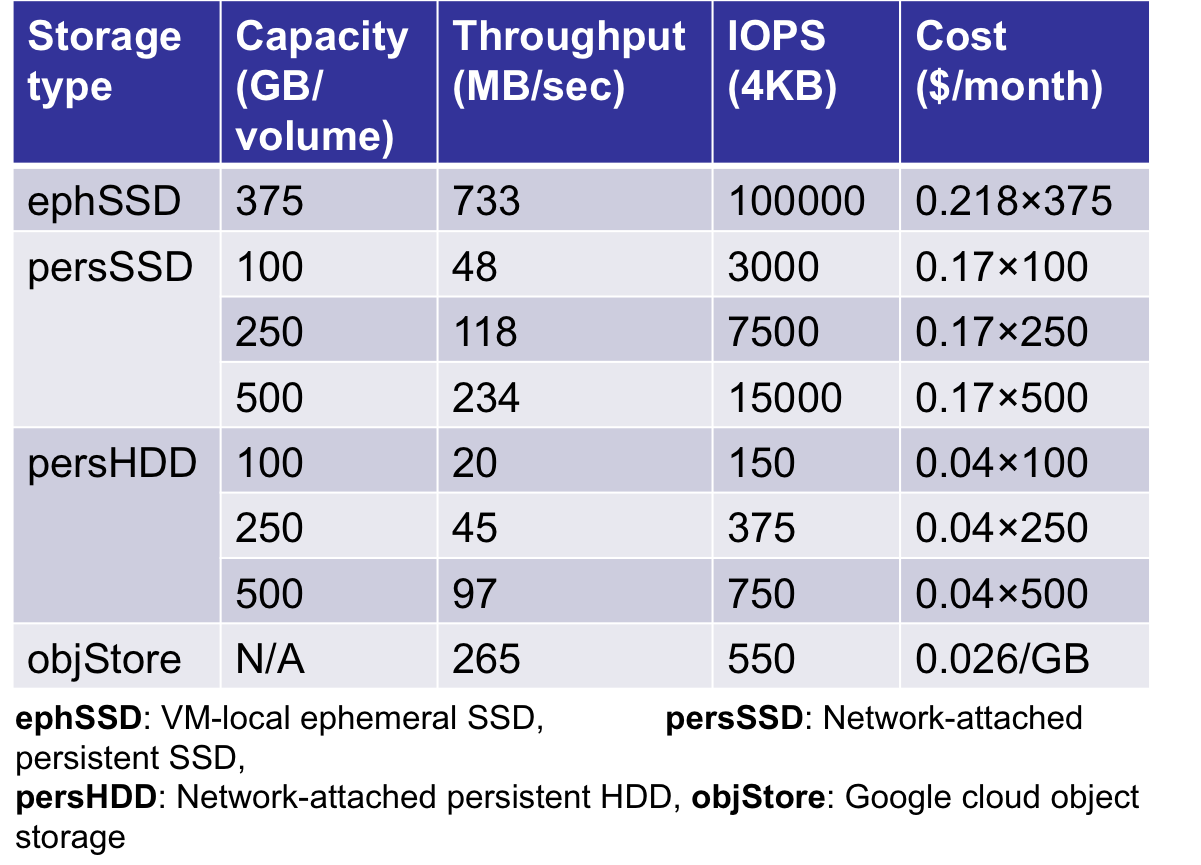
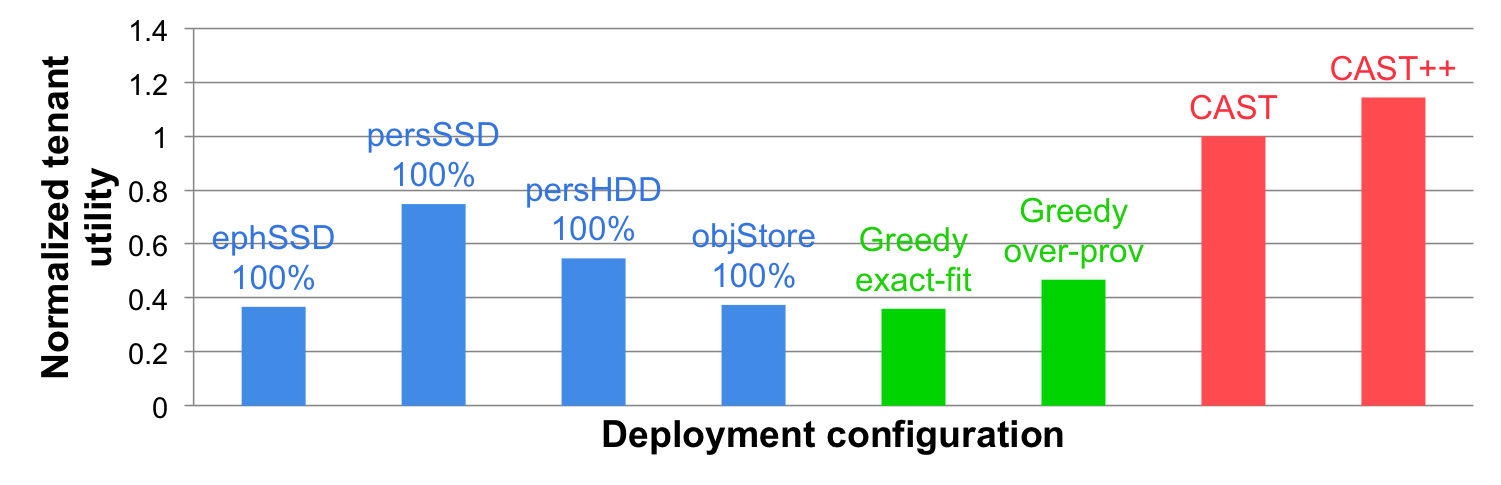
The work on analytics workload management to find a sophisticated tiering strategy that can efficiently utilize all possible storage service options (e.g., virtual machine (VM)-local ephemeral disks, network-attached persistent disks and cloud object store, etc.) to meet the tenant requirement was undertaken. Addressing this problem, we proposed CAST, a cloud storage tiering solution that tenants can leverage to reduce their monetary cost and improve performance of cloud analytics workloads.
We evaluated our CAST system using production workload traces from Facebook and a 400-core Google Cloud based Hadoop cluster. The results demonstrated that Cast++ achieves 1.21x performance and reduces deployment costs by 51.4% compared to local storage configuration. An enhancement, CAST++, extends these capabilities to meet deadlines for analytics workflows while minimizing the cost. The evaluation showed that compared to extant storage-characteristic-oblivious cloud deployment strategies, CAST++ improved the performance by as much as 37.1% while reducing deployment costs by as much as 51.4%.
MOS: Workload-aware Elasticity for Cloud Object Stores[HPDC’16]
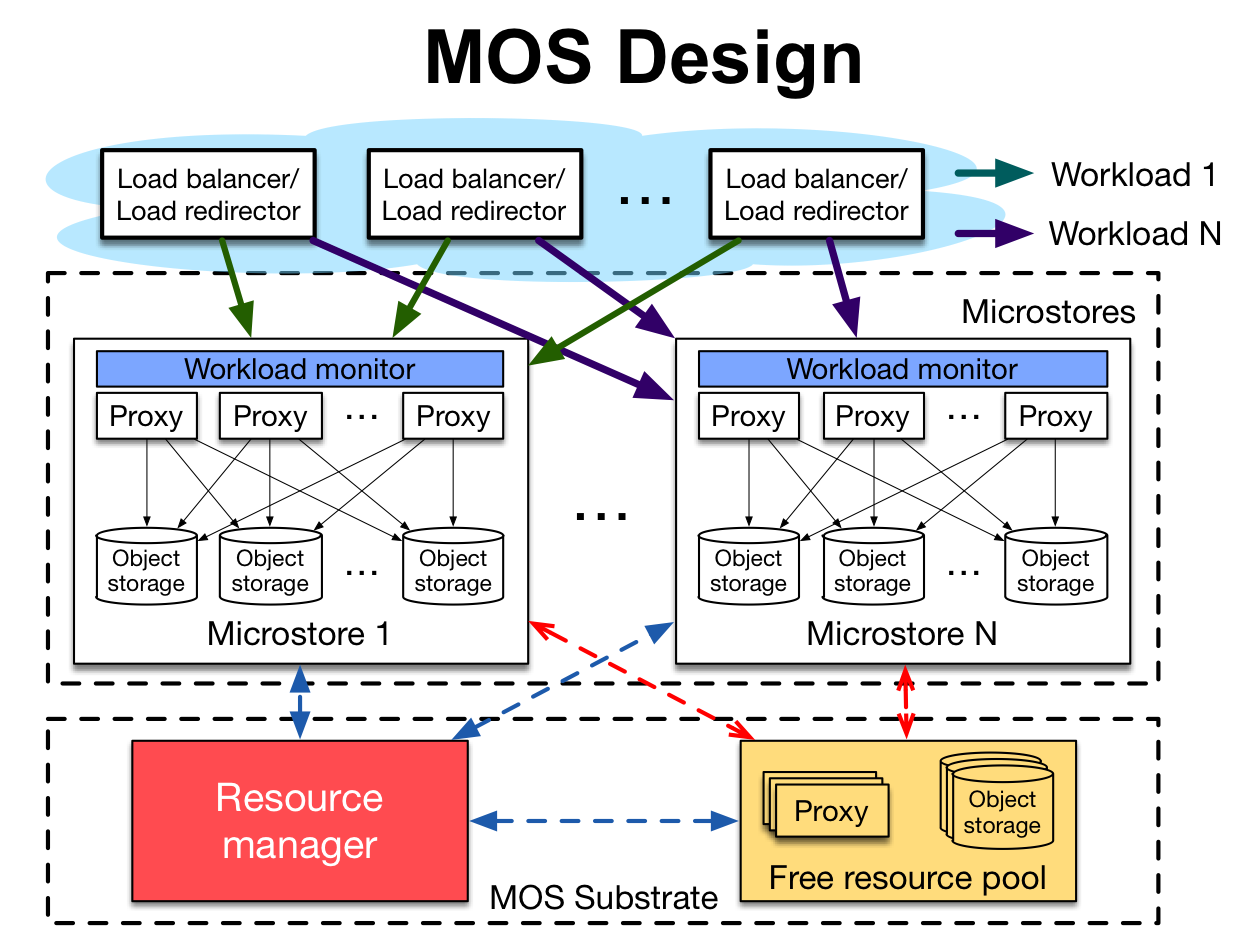
MOS goes beyond extant object store systems and offers a novel solution wherein the traditional monolithic design is dynamically partitioned into multiple fine-grained microstores each serving a different type of workloads. Prototype performance evaluation on a 128-core local testbed shows that compared to the statically configured setup, MOS improves the sustained throughput by 79% for a large-object intensive workload while reducing the 95%-ile tail latency by up to 70% for a small-object intensive workload. Large-scale simulation experiments on a 50 server cluster shows that by utilizing the same set of resources, MOS++, an optimized version that leverages containers to manage resources at fine granularity, achieves up to 18% performance improvement compared to the baseline case MOS.
MOS and its enhancement MOS++, outperforms extant object stores in multi-tenant environments by leveraging containers for fine-grained resource management and higher resource efficiency. We also developed COSPerf, a cloud object store simulator, to further verify the design choices in MOS++ and similar systems.
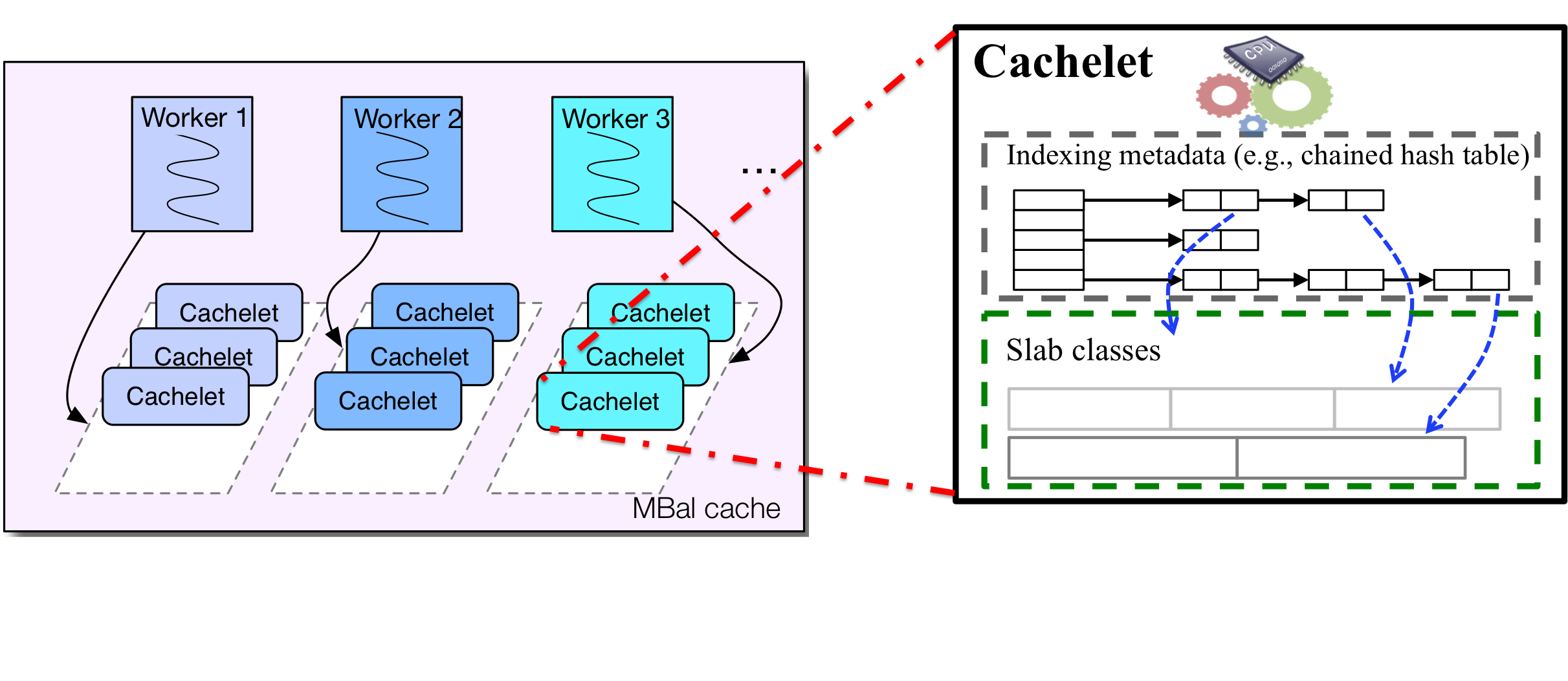
MBal: A Load Balanced Memory Cache Tier[EuroSys’15]
The work on in-memory key value store resulted in a framework called MBAL, which lends itself naturally and flexibly to provide adaptive load balancing both within a server and across the cache cluster through a multi-phase load balancer (e.g., key replication, coordinated data migration, etc.). MBal can dynamically mitigate the imbalance, while supporting high performance and resource utilization efficiency as well as reducing key-value query tail latency.
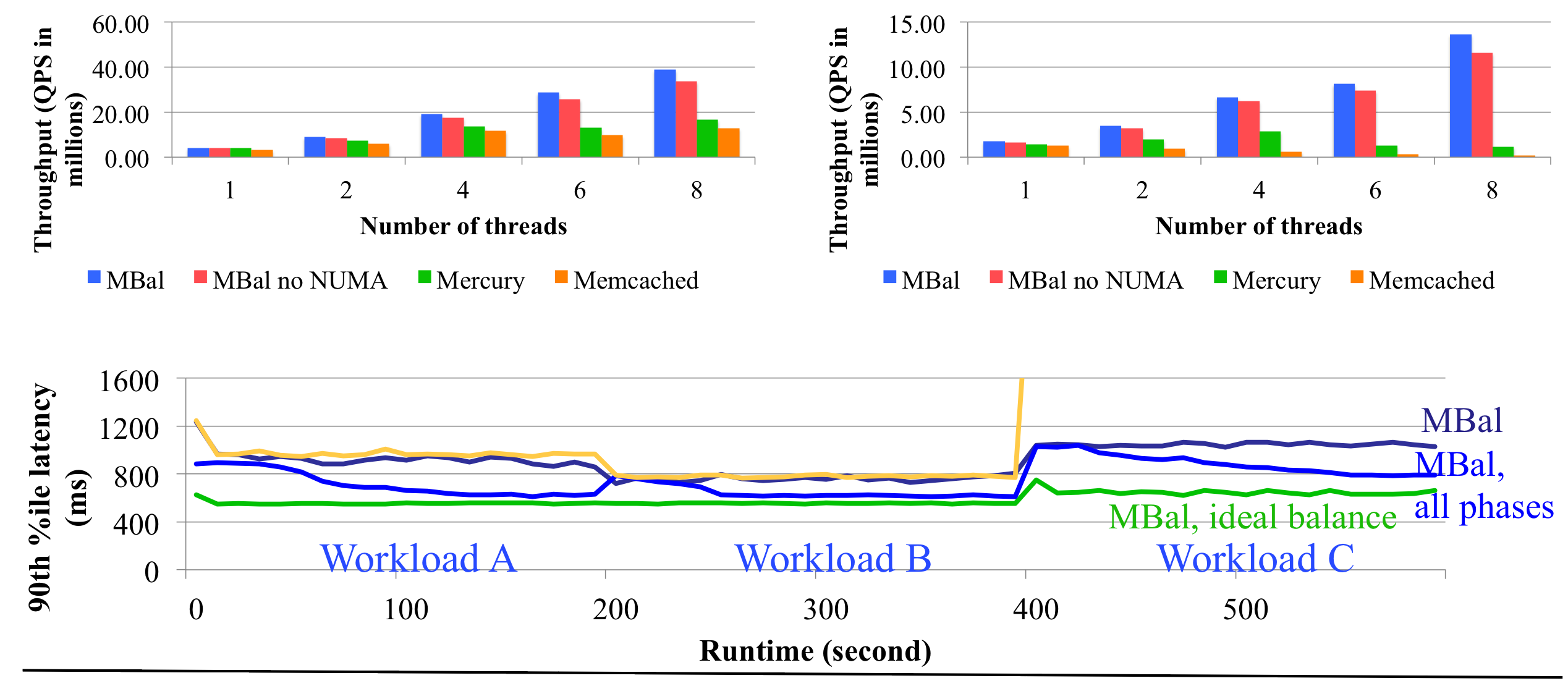
MBal goes beyond extant systems and offers a holistic solution wherein the load balancing model tracks hotspots and applies different strategies based on imbalance severity -- key replication, server-local or cross-server coordinated data migration. Performance evaluation on an 8-core commodity server shows that compared to a state-of-the-art approach, MBal scales with number of cores and executes 2.3x and 12x more queries/second for GET and SET operations, respectively. Furthermore, MBAL also cohesively employs different migration and replication techniques to improve performance by load balancing both within a server and across servers to redistribute and mitigate hotspots. Testing on a cloud-based 20- node cluster demonstrates that each of the considered load balancing techniques effectively complement each other, and compared to Memcached can improve latency and throughput by 35% and 20%, respectively.
Other related projects:
AnalyzeThis: An Analysis Workflow-Aware Storage System [SC’15]: An analysis workflow-aware storage system that seamlessly blends together the flash storage and data analysis.
Multi-tiered Buffer Cache for Persistent Memory Devices: A tiered caching system for combining PM devices to achieve the best of both PCM and FB-DRAM at lower cost-per-GB.
TurnKey: Unlocking Pluggable Distributed Key-Value Stores [HotStorage’16]: A development platform that eases distributed KV store programming by providing common distributed management functionalities.
Scalable Metering Systems [IC2E’15, Cloud’15]: A detailed study of monitoring data collected by OpenStack with a goal to pinpoint the limitations of the current approach and design alternate solutions.
MEMTUNE [IPDPS’16]: Dynamic Memory Management for In-memory Data Analytic Platforms
DUX [CCGrid’16]: An application-attuned dynamic data management system for data processing frameworks
Preliminary results show that ClusterOn incurs negligible overhead and demonstrate its ability to scale up an embedded NoSQL database. Adding distributed management support is the focus of our ongoing research.
Evaluation of our integrated data services of TagIt shows 10x performance improvement over extant HPC and cloud data service engines that utilize separate data searching and metadata indexing approaches.
MOS goes beyond extant object store systems and offers a novel solution wherein the traditional monolithic design is dynamically partitioned into multiple fine-grained microstores each serving a different type of workloads. Prototype performance evaluation on a 128-core local testbed shows that compared to the statically configured setup, MOS improves the sustained throughput by 79% for a large-object intensive workload while reducing the 95%-ile tail latency by up to 70% for a small-object intensive workload. Large-scale simulation experiments on a 50 server cluster shows that by utilizing the same set of resources, MOS++, an optimized version that leverages containers to manage resources at fine granularity, achieves up to 18% performance improvement compared to the baseline case MOS.
Our preliminary evaluation for cloud monitoring solutions in OpenStack reveals that it is possible to reduce the monitored data size by up to 80% and missed anomaly detection rate from 3% to as low as 0.05% to 0.1%.
Evaluation of DUX with trace-driven simulations using synthetic Facebook workloads reveals that even when using 5.5 times fewer SSDs compared to a SSD-only solution, DUX incurs only a small (5%) performance overhead, and thus offers an affordable and efficient storage tier management.
Evaluation of MEMTUNE in Spark on a commodity server using representative and diverse workloads from SparkBench demonstrates that with dynamic managed memory cache management and workload aware data caching policy, MEMTUNE can reduce workload execution time by up to 46% by detecting the desired memory demand for both tasks and data persistence. Moreover, MEMTUNE improves memory hit ratio by 41% by using workload-aware data caching policy.
MBal goes beyond extant systems and offers a holistic solution wherein the load balancing model tracks hotspots and applies different strategies based on imbalance severity -- key replication, server-local or cross-server coordinated data migration. Performance evaluation on an 8-core commodity server shows that compared to a state-of-the-art approach, MBal scales with number of cores and executes 2.3x and 12x more queries/second for GET and SET operations, respectively. Furthermore, MBAL also cohesively employs different migration and replication techniques to improve performance by load balancing both within a server and across servers to redistribute and mitigate hotspots. Testing on a cloud-based 20- node cluster demonstrates that each of the considered load balancing techniques effectively complement each other, and compared to Memcached can improve latency and throughput by 35% and 20%, respectively.
We evaluated our CAST system using production workload traces from Facebook and a 400-core Google Cloud based Hadoop cluster. The results demonstrated that Cast++ achieves 1.21x performance and reduces deployment costs by 51.4% compared to local storage configuration. An enhancement, CAST++, extends these capabilities to meet deadlines for analytics workflows while minimizing the cost. The evaluation showed that compared to extant storage-characteristic-oblivious cloud deployment strategies, CAST++ improved the performance by as much as 37.1% while reducing deployment costs by as much as 51.4%.
The results of study of Active Flash showed that analysis-awareness can be built into each and every layer of a storage system. Our evaluation of AnalyzeThis showed that is viable, and can be used to capture complex workflows.
We evaluated φSched using experiments on Amazon EC2 with four clusters of eight homogeneous nodes each, where each cluster has a different hardware configuration. We found that φSched’s optimized placement of applications across the test clusters reduces the execution time of the test applications by 18.7%, on average, when compared to extant hardware oblivious scheduling. Moreover, our HDFS enhancement increased the I/O throughput by up to 23% and the average I/O rate by up to 26% for the TestDFSIO benchmark. Similarly, VENU on a medium-sized cluster achieved 11% improvement in application completion times by using only 10% of the SSD based available storage.
Our approach and workflow-aware analysis system will reduce time-to-solution for running simulations and models by supporting easy-to-use and easy-to-program distributed software frameworks. Such system models enable highly efficient and scalable computing applications, which in turn will impact society profoundly, e.g., by enabling faster discovery of new drugs for ailments or exposing a new physical phenomenon. Thus, our research shares its impacts on society with others who focus on the improvement of computer based modeling for scientific discovery. It has a huge potential to improve the quality of life.
Hyogi Sim, Youngjae Kim, Sudharshan S. Vazhkudai, Geoffroy R. Vallee, Seung-Hwan Lim, and Ali R. Butt. TagIt: A Fast and Efficient Scientific Data Discovery Service. To appear in Proceedings of the 2017 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (SC'17), Denver, CO, pages 10, November 2017. (AR:18.7%).
Ali Anwar, Yue Cheng, Aayush Gupta, and Ali R. Butt. MOS: Workload-aware Elasticity for Cloud Object Stores. In Proceedings of the 25th ACM Symposium on High-Performance Parallel and Distributed Computing (HPDC), Kyoto, Japan, pages 12, May 2016. (AR: 15.5%). An initial design, Taming the Cloud Object Storage with MOS, appeared in Proceedings of the 10th Parallel Data Storage Workshop (PDSW), Austin, Texas, pages 6, November 2015. (AR: 36%). A related poster was presented in 6th ACM SIGOPS Asia-Pacific Workshop on Systems (APSys 2015), Tokyo, Japan, July 2015.
Yue Cheng, M. Safdar Iqbal, Aayush Gupta, and Ali R. Butt. Provider versus Tenant Pricing Games for Hybrid Object Stores in the Cloud. In IEEE Internet Computing: Special Issue on Cloud Storage, 20(3):28-35, May/June 2016. [Link to paper]
Ali Anwar, Yue Cheng, and Ali R. Butt. Towards Managing Variability in the Cloud. In Proceedings of the 1st IEEE International Workshop on Variability in Parallel and Distributed Systems (VarSys), Chicago, IL, pages 4, May 2016.
Krish K. R., Bharti Wadhwa, M. Safdar Iqbal, M. Mustafa Rafique, and Ali R. Butt. On Efficient Hierarchical Storage for Big Data Processing. In 16th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), Cartagena, Colombia, pages 6, May 2016. (AR: 36%).
Hyogi Sim, Youngjae Kim, Sudharshan S. Vazhkudai, Devesh Tiwari, Ali Anwar, Ali R. Butt, and Lavanya Ramakrishnan. AnalyzeThis: An Analysis Workflow-Aware Storage System. In Proceedings of the 2015 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (SC'15), Austin, TX, pages 12, Nov. 2015. (AR: 22.1%).
Min Li, Dakshi Agrawal, Frederick Reiss, Berni Schiefer, Ali R. Butt, Josep Lluis Larriba Pey, Francois Raab, Doshi Kshitij and Yinglong Xia. SparkBench: A Spark Performance Testing Suite. In Proceedings of the Seventh TPC Technology Conference on Performance Evaluation & Benchmarking (TPCTC 2015), Kohala Coast, HI, pages 20, August 2015.
Hyogi Sim, Youngjae Kim, Sudharshan S. Vazhkudai, Devesh Tiwari, Ali Anwar, Ali R. Butt, and Lavanya Ramakrishnan. AnalyzeThis: An Analysis Workflow-Aware Storage System. Poster in the 2015 USENIX Annual Technical Conference (ATC), Santa Clara, CA, July 2015.
Yue Cheng, M. Safdar Iqbal, Aayush Gupta, and Ali R. Butt. CAST: Tiering Storage for Data Analytics in the Cloud. In Proceedings of the International ACM Symposium on High-Performance Distributed Computing (HPDC), Portland, Oregon, pages 12, June 2015. (AR: 16.4%).
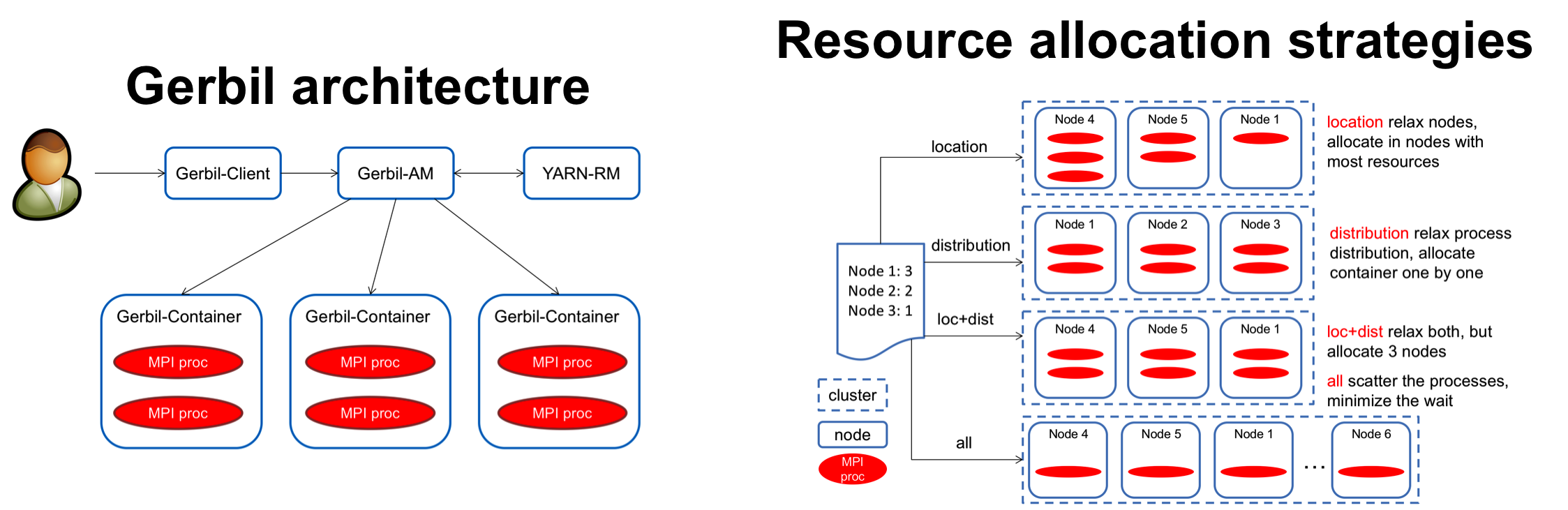
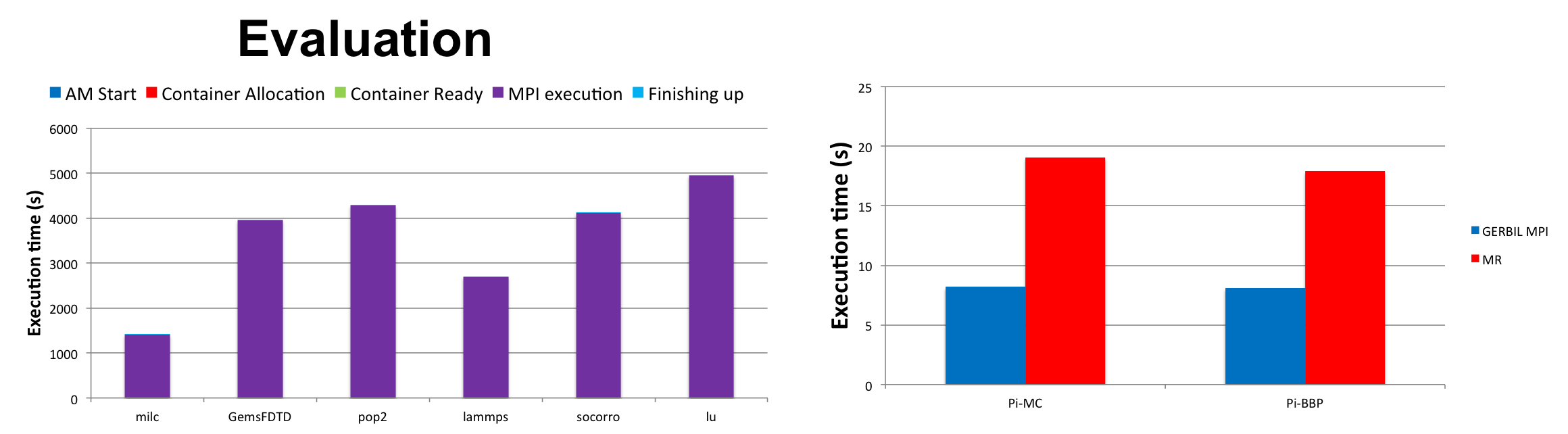
Luna Xu, Min Li, and Ali R. Butt. Gerbil: MPI+YARN. In Proceedings of the IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), Shenzhen, Guangdong, China, pages 10, May 2015. (AR: 25.7%).
Shengjian Guo, Markus Kusano, Chao Wang, Zijiang Yang, and Aarti Gupt. Assertion guided symbolic execution of multithreaded programs. In Proceedings of the ACM SIGSOFT Symposium on Foundations of Software Engineering (FSE), Bergamo, Italy, September 2015.
Naling Zhang, Markus Kusano, and Chao Wang. Dynamic partial order reduction for relaxed memory models. In Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), Portland, OR, June 2015.
Tariq Kamal, Ali R. Butt, Keith Bisset, and Madhav Marathe. Cost Estimation of Parallel Constrained Producer-Consumer Algorithms. In Proceedings of the 23rd Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), Turku, Finland, pages 8, February 2015. (AR: 28.0%). An earlier version of the paper, Load Analysis and Cost Estimation of Parallel Constrained Producer-Consumer Algorithms, appeared in Proceedings of the IEEE International Conference on Cluster Computing (Cluster), Madrid, Spain, pages 286--287, September 2014.
Krish K. R., M. Safdar Iqbal, M. Mustafa Rafique and Ali R. Butt. Towards Energy Awareness in Hadoop. In Proceedings of the Fourth International Workshop on Network-Aware Data Management (NDM) @SC'14, New Orleans, LA, pages 16-22, November 2014. (AR: 45.5%).
Krish K. R., M. Safdar Iqbal, and Ali R. Butt. VENU: Orchestrating SSDs in Hadoop Storage. Short paper in Proceedings of the IEEE International Conference on Big Data (BigData), Washington, DC, pages 207-212, October 2014. (AR: 40.2%).